
Pengelompokan Hasil Panen Kelapa Sawit Dalam Produksi Per Blok Menggunakan Algoritma K-Means
Grouping of Palm Oil Harvests in Production Per Block Using the K-Means Algorithm
-
Agustina Lili
*
 STIKOM Tunas Bangsa, Pematangsiantar,
Indonesia
STIKOM Tunas Bangsa, Pematangsiantar,
Indonesia
- Suhada STIKOM Tunas Bangsa, Pematangsiantar, Indonesia
- Saputra Widodo STIKOM Tunas Bangsa, Pematangsiantar, Indonesia
Abstract
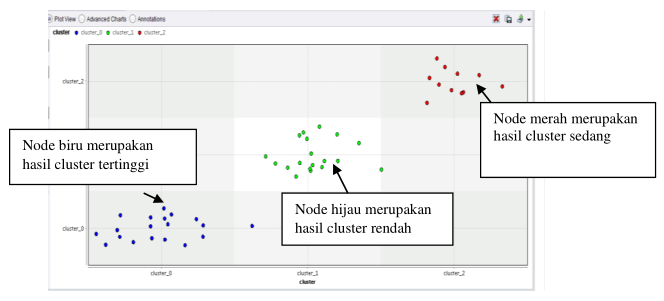
The palm oil yield is essential for a palm oil company, especially at PT. Surya Intisari Raya Sei Mandau. This is evidenced when the author tries to randomly determine the starting point of the cluster center from one of the computational starting objects. The number of cluster memberships generated is the same when using other data as the starting point for the cluster center. However, this only affects the amount of literacy carried out. Data grouping (object Clustering) is one of the processes of object mining that aims to partition existing data into one or more data clusters based on their characteristics. The K-Means algorithm in oil palm yields in production per block based on the variables formed per block for each PT. Surya Intisari Raya Sei Mandau. Grouping of oil palm yields at PT. Surya Intisari Raya Sei Mandau using the K-Means method is carried out through 4 stages, namely: name per block, year of plant, afdeling, and area (Ha) and is divided into 3 clusters, namely cluster 1 high, cluster 2 medium, and cluster 3 low.
References
Y. D. Darmi and A. Setiawan, “Penerapan Metode Clustering K-Means Dalam Pengelompokan Penjualan Produk,” J. Media Infotama, vol. 12, no. 2, pp. 148–157, 2017, doi: 10.37676/jmi.v12i2.418.
S. S. Helma, R. R. R, and E. Normala, “Clustering pada Data Fasilitas Pelayanan Kesehatan Kota Pekanbaru Menggunakan Algoritma K - Means,” no. November, pp. 131–137, 2019.
M. A. W. K. MURTI, “Penerapan Metode K-Means Clustering Untuk Mengelompokan Potensi Produksi Buah – Buahan Di Provinsi Daerah Istimewa Yogyakarta,” Skripsi, 2017.
L. Maulida, P. Studi, and M. Informatika, “KUNJUNGAN WISATAWAN KE OBJEK WISATA UNGGULAN DI PROV . DKI JAKARTA DENGAN K-MEANS,” vol. 2, no. 3, pp. 167–174, 2018.
Y. D. Darmi and A. Setiawan, “Penerapan Metode Clustering K-Means Dalam Pengelompokan Penjualan Produk,” J. Media Infotama, vol. 12, no. 2, pp. 148–157, 2017, doi: 10.37676/jmi.v12i2.418.
S. Handoko, F. Fauziah, and E. T. E. Handayani, “Implementasi Data Mining Untuk Menentukan Tingkat Penjualan Paket Data Telkomsel Menggunakan Metode K-Means Clustering,” J. Ilm. Teknol. dan Rekayasa, vol. 25, no. 1, pp. 76–88, 2020, doi: 10.35760/tr.2020.v25i1.2677.
M. Lailil, ratnawati eka Dian, and putri mardi regasari Rekyan, Data Mining. UB Press, 2018.
M. Nasution, D. Irmayani, R. Watrianthos, S. Suryadi, and I. R. Munthe, “Comparative Analysis Of Data Mining Using The Rought Set Method With K-Means Method,” Int. J. Sci. Technol. Res., vol. 8, no. 05, pp. 38–40, 2019, [Online]. Available: http://www.ijstr.org/final-print/may2019/Comparative-Analysis-Of-Data-Mining-Using-The-Rought-Set-Method-With-K-means-Method.pdf.
W. Dhuhita, “Clustering Menggunakan Metode K-Mean Untuk Menentukan Status Gizi Balita,” J. Inform. Darmajaya, vol. 15, no. 2, pp. 160–174, 2015.
S. S. Helma, R. R. R, and E. Normala, “Clustering pada Data Fasilitas Pelayanan Kesehatan Kota Pekanbaru Menggunakan Algoritma K - Means,” no. November, pp. 131–137, 2019.
I. Parlina, W. A. Perdana, W. Anjar, and L. Ridwan.M, “MEMANFAATKAN ALGORITMA K-MEANS DALAM MENENTUKAN PEGAWAI YANG LAYAK MENGIKUTI ASESSMENT CENTER,” vol. 3, no. 1, pp. 87–93, 2018.
Authors who publish with this journal agree to the following terms:
- Authors retain copyright and grant the journal right of first publication with the work simultaneously licensed under Creative Commons Attribution 4.0 International License that allows others to share the work with an acknowledgment of the work's authorship and initial publication in this journal.
- Authors are able to enter into separate, additional contractual arrangements for the non-exclusive distribution of the journal's published version of the work (e.g., post it to an institutional repository or publish it in a book), with an acknowledgment of its initial publication in this journal.
- Authors are permitted and encouraged to post their work online (e.g., in institutional repositories or on their website) prior to and during the submission process, as it can lead to productive exchanges, as well as earlier and greater citation of published work (Refer to The Effect of Open Access).

